Can you remember, off the top of your head, what you were doing at this date and time two months ago? What about just two weekends ago? It is surprising to me how rarely people journal when our memories are so ephemeral. We have new thoughts, experiences, and conversations every day, yet we save and reflect on so few of them.
Journaling is one effective way to take control of your life and memories. Although taking photos and videos are more common ways to keep track of what you do or see, I’ve found writing to be more effective when it comes to reflecting on my life and staying organized.
People I’ve spoken to on this subject are generally receptive to the concept of journaling, but many find it difficult to prioritize the activity and keep a routine. I personally journal about once a week, filling in several days at a time. After a few months, it’s fulfilling to go back and revisit old entries. It’s amazing how a few short sentences can bring you back to an amazing conversation with a close friend, or your mood on a sunny, relaxing day, for example.
For me, one of the biggest starting hurdles was choosing the proper journaling medium. There are countless apps out there, but many of them have inconvenient tradeoffs. Apps often make it difficult to export your data, get in your way with ads, or keep useful features behind paywalls. There’s always pen and paper, but while writing by hand can be relaxing, it is also slower than typing, difficult to search through, and hard to preserve through the years.
Journaling in Markdown
My solution for the past year and a half has been to journal digitally in Markdown files. Markdown is designed to be easy-to-read, easy-to-write, and it avoids the pitfalls I mentioned above. Here’s a example of how I journal, albeit somewhat contrived and with less detail:
## Mon 29
* __exercise__ 7 minute workout
* Skyped with X. It was the first time we caught up in a while! We talked about our living situations, our jobs, and what we've been spending our spare time doing these past few months.
* Met up with Y at Cafe Cesura. Worked on a blog post about journaling.
Which converts into the following HTML:
Mon 29
- exercise 7 minute workout
- Skyped with X. It was the first time we caught up in a while! We talked about our living situations, our jobs, and what we’ve been spending our spare time doing these past few months.
- Met up with Y. at Cafe Cesura. Worked on a blog post about journaling.
Markdown’s lightweight structure provides both organization and flexibility. I generally use headers for dates, followed by bullet points describing each significant event of the day. I keep each month in a separate file, and each year of files in a distinct folder.
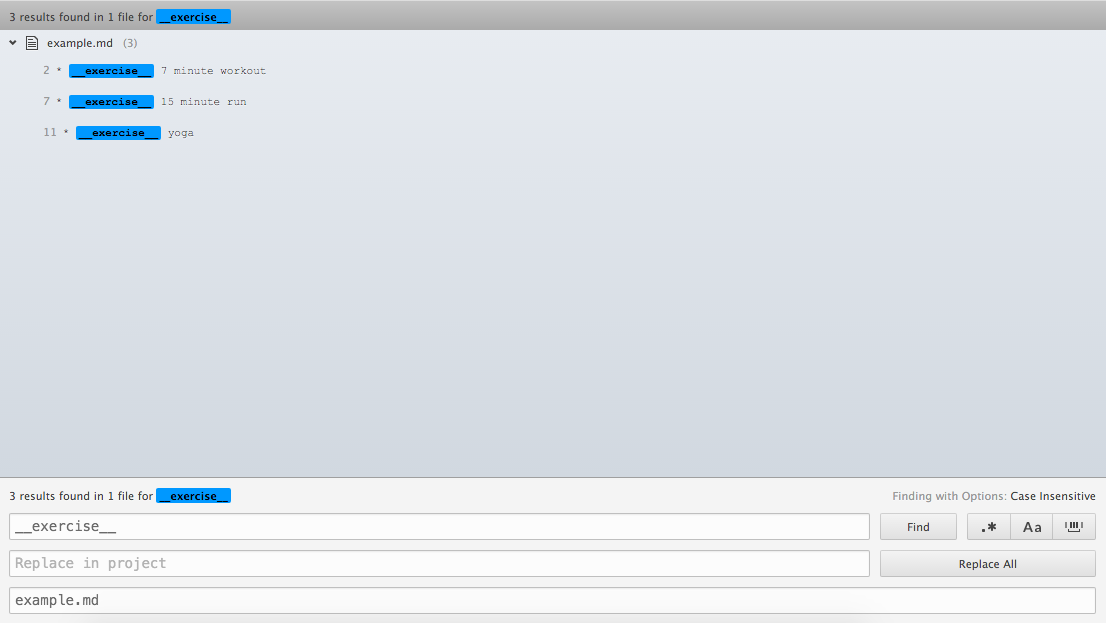
I also use tags like __exercise__ above to mark certain categories of events or thoughts. This has an added benefit of being easily searchable in Atom, my text editor of choice for journaling.
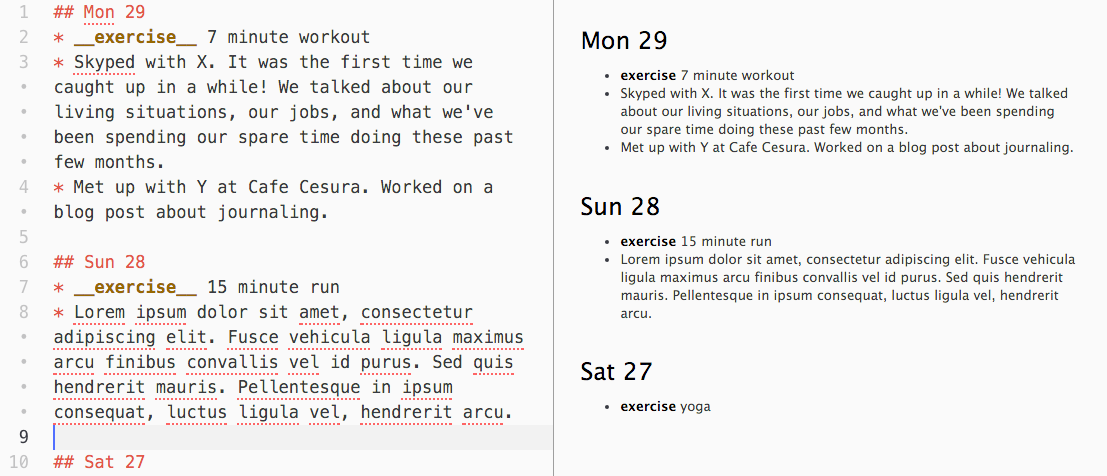
Atom also provides a handy Markdown preview:
Using Markdown, I can write faster than on paper, search through my notes quickly, and save backup copies easily. I don’t have to rely on any apps, nor give any third parties ownership of my data.
A year and a half of Markdown
As I mentioned earlier, I’ve been journaling in markdown for the past 1.5 years, and I’m really enjoying the setup. I journal approximately once a week, but I’ve been trying to increase the frequency. The amount of information I retain about a particular day significantly diminishes by the third passing day.
Perspectives on time and value
Journaling has given me a much better higher-level understanding of where my time goes and more importantly, what I value. Keeping the one folder per year structure I have now, I’ll have 60 folders of journal files, give or take, by the end of my life. That’s not a lot, all things considered, and made me think about what I want to accomplish and record in my lifetime.
Handwritten notes are still cool
Digital journaling hasn’t completely replaced pen and paper. I still take handwritten notes in pocket notepads to remember things to do, books to read, or random thoughts. More often than not, I’ll transfer the interesting portions into my journal.
What’s next
There are other sources of data besides journaling that I want to pull together to form a richer picture. Photos, calendars, conversations, and geotags would add a lot of context to my journal.
To this end, I started writing a parser in Python for the Markdown-generated HTML files. The output is a Python object, which I can work with programmatically. As an example use case, I’ll be able to match up a given date with photos taken on that date in Google Photos. Ultimately, I hope to put together a simple webpage to show what I was up to on a given date in every year of my life.
If you liked this post, you may also like this one I wrote on how I keep a calendar.