
|
Neural Grasp Distance Fields for Robot Manipulation
Thomas Weng, David Held, Franziska Meier, Mustafa Mukadam
@article{weng2023ngdf,
title={Neural Grasp Distance Fields for Robot Manipulation},
author={Weng, Thomas and Held, David and Meier, Franziska and Mukadam, Mustafa},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2023}
}
We formulate grasp learning as a neural field and present Neural Grasp Distance Fields (NGDF). Here, the input is a 6D pose of a robot end effector and output is a distance to a continuous manifold of valid grasps for an object. In contrast to current approaches that predict a set of discrete candidate grasps, the distance-based NGDF representation is easily interpreted as a cost, and minimizing this cost produces a successful grasp pose. This grasp distance cost can be incorporated directly into a trajectory optimizer for joint optimization with other costs such as trajectory smoothness and collision avoidance. During optimization, as the various costs are balanced and minimized, the grasp target is allowed to smoothly vary, as the learned grasp field is continuous. In simulation benchmarks with a Franka arm, we find that joint grasping and planning with NGDF outperforms baselines by 63% execution success while generalizing to unseen query poses and unseen object shapes.
International Conference on Robotics and Automation (ICRA), 2023
|

|
Learning to Singulate Layers of Cloth based on Tactile Feedback
Sashank Tirumala*, Thomas Weng*, Daniel Seita*, Oliver Kroemer, Zeynep Temel, David Held
@INPROCEEDINGS{tirumala2022reskin,
author={Tirumala, Sashank and Weng, Thomas and Seita, Daniel and Kroemer, Oliver and Temel, Zeynep and Held, David},
booktitle={2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={Learning to Singulate Layers of Cloth using Tactile Feedback},
year={2022},
volume={},
number={},
pages={7773-7780},
doi={10.1109/IROS47612.2022.9981341}
}
Robotic manipulation of cloth has applications ranging from fabrics manufacturing to handling blankets and laundry. Cloth manipulation is challenging for robots largely due to their high degrees of freedom, complex dynamics, and severe self-occlusions when in folded or crumpled configurations. Prior work on robotic manipulation of cloth relies primarily on vision sensors alone, which may pose challenges for fine-grained manipulation tasks such as grasping a desired number of cloth layers from a stack of cloth. In this paper, we propose to use tactile sensing for cloth manipulation; we attach a tactile sensor (ReSkin) to one of the two fingertips of a Franka robot and train a classifier to determine whether the robot is grasping a specific number of cloth layers. During test-time experiments, the robot uses this classifier as part of its policy to grasp one or two cloth layers using tactile feedback to determine suitable grasping points. Experimental results over 180 physical trials suggest that the proposed method outperforms baselines that do not use tactile feedback and has a better generalization to unseen fabrics compared to methods that use image classifiers.
International Conference on Intelligent Robots and Systems (IROS), 2022 - Best Paper at ROMADO-SI
|

|
FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy
Thomas Weng, Sujay Bajracharya, Yufei Wang, David Held
@inproceedings{weng2021fabricflownet,
title={FabricFlowNet: Bimanual Cloth Manipulation
with a Flow-based Policy},
author={Weng, Thomas and Bajracharya, Sujay and
Wang, Yufei and Agrawal, Khush and Held, David},
booktitle={Conference on Robot Learning},
year={2021}
}
We address the problem of goal-directed cloth manipulation, a challenging task due to the deformability of cloth. Our insight is that optical flow, a technique normally used for motion estimation in video, can also provide an effective representation for corresponding cloth poses across observation and goal images. We introduce FabricFlowNet (FFN), a cloth manipulation policy that leverages flow as both an input and as an action representation to improve performance. FabricFlowNet also elegantly switches between dual-arm and single-arm actions based on the desired goal. We show that FabricFlowNet significantly outperforms state-of-the-art model-free and model-based cloth manipulation policies. We also present real-world experiments on a bimanual system, demonstrating effective sim-to-real transfer. Finally, we show that our method generalizes when trained on a single square cloth to other cloth shapes, such as T-shirts and rectangular cloths.
Conference on Robot Learning (CoRL), 2021
|

|
Cloth Region Segmentation for Robust Grasp Selection
Jianing Qian*, Thomas Weng*, Luxin Zhang, Brian Okorn, David Held
@InProceedings{Qian_2020_IROS,
author={Qian, Jianing and Weng, Thomas and Zhang, Luxin and Okorn, Brian and Held, David},
booktitle={2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={Cloth Region Segmentation for Robust Grasp Selection},
year={2020},
volume={},
number={},
pages={9553-9560},
doi={10.1109/IROS45743.2020.9341121}
}
Cloth detection and manipulation is a common task in domestic and industrial settings, yet such tasks remain a challenge for robots due to cloth deformability. Furthermore, in many cloth-related tasks like laundry folding and bed making, it is crucial to manipulate specific regions like edges and corners, as opposed to folds. In this work, we focus on the problem of segmenting and grasping these key regions. Our approach trains a network to segment the edges and corners of a cloth from a depth image, distinguishing such regions from wrinkles or folds. We also provide a novel algorithm for estimating the grasp location, direction, and directional uncertainty from the segmentation. We demonstrate our method on a real robot system and show that it outperforms baseline methods on grasping success. Video and other supplementary materials are available at: https://github.com/thomasweng15/cloth-segmentation.
International Conference on Intelligent Robots and Systems (IROS), 2020
|

|
Multi-Modal Transfer Learning for Grasping Transparent and Specular Objects
Thomas Weng, Amith Pallankize, Yimin Tang, Oliver Kroemer, David Held
@ARTICLE{9001238,
author={Thomas Weng and Amith Pallankize and Yimin Tang and Oliver Kroemer and David Held},
journal={IEEE Robotics and Automation Letters},
title={Multi-Modal Transfer Learning for Grasping Transparent and Specular Objects},
year={2020},
volume={5},
number={3},
pages={3791-3798},
doi={10.1109/LRA.2020.2974686}
}
State-of-the-art object grasping methods rely on depth sensing to plan robust grasps, but commercially available depth sensors fail to detect transparent and specular objects. To improve grasping performance on such objects, we introduce a method for learning a multi-modal perception model by bootstrapping from an existing uni-modal model. This transfer learning approach requires only a pre-existing uni-modal grasping model and paired multi-modal image data for training, foregoing the need for ground-truth grasp success labels nor real grasp attempts. Our experiments demonstrate that our approach is able to reliably grasp transparent and reflective objects. Video and supplementary material are available at https://sites.google.com/view/transparent-specular-grasping.
Robotics and Automation Letters (RAL) with presentation at the International Conference of Robotics and Automation (ICRA), 2020
|

|
Robot Object Referencing through Legible Situated Projections
Thomas Weng, Leah Perlmutter, Stefanos Nikolaidis, Siddhartha Srinivasa, Maya Cakmak
@INPROCEEDINGS{8793638,
author={Weng, Thomas and Perlmutter, Leah and Nikolaidis, Stefanos and Srinivasa, Siddhartha and Cakmak, Maya},
booktitle={2019 International Conference on Robotics and Automation (ICRA)},
title={Robot Object Referencing through Legible Situated Projections},
year={2019},
volume={},
number={},
pages={8004-8010},
doi={10.1109/ICRA.2019.8793638}
}
The ability to reference objects in the environment is a key communication skill that robots need for complex, task-oriented human-robot collaborations. In this paper we explore the use of projections, which are a powerful communication channel for robot-to-human information transfer as they allow for situated, instantaneous, and parallelized visual referencing. We focus on the question of what makes a good projection for referencing a target object. To that end, we mathematically formulate legibility of projections intended to reference an object, and propose alternative arrow-object match functions for optimally computing the placement of an arrow to indicate a target object in a cluttered scene. We implement our approach on a PR2 robot with a head-mounted projector. Through an online (48 participants) and an in-person (12 participants) user study we validate the effectiveness of our approach, identify the types of scenes where projections may fail, and characterize the differences between alternative match functions.
IEEE International Conference on Robotics and Automation (ICRA), 2019
|
|
RobotIST: Interactive Situated Tangible Robot Programming
Yasaman S Sefidgar*, Thomas Weng*, Heather Harvey, Sarah Elliott, Maya Cakmak
@inproceedings{10.1145/3267782.3267921,
author = {Sefidgar, Yasaman S. and Weng, Thomas and Harvey, Heather and Elliott, Sarah and Cakmak, Maya},
title = {RobotIST: Interactive Situated Tangible Robot Programming},
year = {2018},
isbn = {9781450357081},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3267782.3267921},
doi = {10.1145/3267782.3267921},
booktitle = {Proceedings of the 2018 ACM Symposium on Spatial User Interaction},
pages = {141–149},
numpages = {9},
keywords = {Robot Programming, Transparency, Situated Programming, Direct Manipulation, Tangible Programming},
location = {Berlin, Germany},
series = {SUI '18}
}
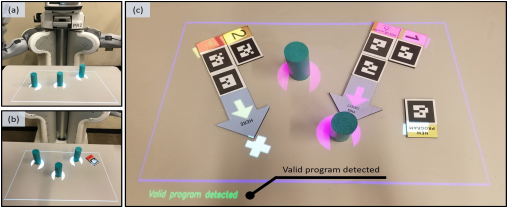
Situated tangible robot programming allows programmers to reference parts of the workspace relevant to the task by indicating objects, locations, and regions of interest using tangible blocks. While it takes advantage of situatedness compared to traditional text-based and visual programming tools, it does not allow programmers to inspect what the robot detects in the workspace, nor to understand any programming or execution errors that may arise. In this work we propose to use a projector mounted on the robot to provide such functionality. This allows us to provide an interactive situated tangible programming experience, taking advantage of situatedness, both in user input and system output, to reference parts of the robot workspace. We describe an implementation and evaluation of this approach, highlighting its differences from traditional robot programming.
Proceedings of the Symposium on Spatial User Interaction (SUI), 2018
|

|
Modeling communicative behaviors for object references in human-robot interaction
Henny Admoni, Thomas Weng, Brian Scassellati
@conference{Admoni-2016-113236,
author = {Henny Admoni and Thomas Weng and Brian Scassellati},
title = {Modeling communicative behaviors for object references in human-robot interaction},
booktitle = {Proceedings of (ICRA) International Conference on Robotics and Automation},
year = {2016},
month = {May},
pages = {3352 - 3359},
}
This paper presents a model that uses a robot's verbal and nonverbal behaviors to successfully communicate object references to a human partner. This model, which is informed by computer vision, human-robot interaction, and cognitive psychology, simulates how low-level and high-level features of the scene might draw a user's attention. It then selects the most appropriate robot behavior that maximizes the likelihood that a user will understand the correct object reference while minimizing the cost of the behavior. We present a general computational framework for this model, then describe a specific implementation in a human-robot collaboration. Finally, we analyze the model's performance in two human evaluations-one video-based (75 participants) and one in person (20 participants)-and demonstrate that the system predicts the correct behaviors to perform successful object references.
IEEE International Conference on Robotics and Automation (ICRA), 2016
|

|
Robot nonverbal behavior improves task performance in difficult collaborations
Henny Admoni, Thomas Weng, Bradley Hayes, Brian Scassellati
@INPROCEEDINGS{7451733,
author={Admoni, Henny and Weng, Thomas and Hayes, Bradley and Scassellati, Brian},
booktitle={2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI)},
title={Robot nonverbal behavior improves task performance in difficult collaborations},
year={2016},
volume={},
number={},
pages={51-58},
doi={10.1109/HRI.2016.7451733}
}
Nonverbal behaviors increase task efficiency and improve collaboration between people and robots. In this paper, we introduce a model for generating nonverbal behavior and investigate whether the usefulness of nonverbal behaviors changes based on task difficulty. First, we detail a robot behavior model that accounts for top-down and bottom-up features of the scene when deciding when and how to perform deictic references (looking or pointing). Then, we analyze how a robot's deictic nonverbal behavior affects people's performance on a memorization task under differing difficulty levels. We manipulate difficulty in two ways: by adding steps to memorize, and by introducing an interruption. We find that when the task is easy, the robot's nonverbal behavior has little influence over recall and task completion. However, when the task is challenging- because the memorization load is high or because the task is interrupted-a robot's nonverbal behaviors mitigate the negative effects of these challenges, leading to higher recall accuracy and lower completion times. In short, nonverbal behavior may be even more valuable for difficult collaborations than for easy ones.
11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2016
|

